 RSS
RSS














حرکات گلوی انسان جهت آشکار نمودن صدایش هنگام سخن گفتن رمزگشایی شده است.
استراقسمع کنندگان ممکن است دیگر مجبور نباشند برای شنیدن مکالمات دوردست لبخوانی کنند. با استفاده از یک دوربین با سرعت بالا که در گلو قرار میگیرد، دانشمندان توانستهاند کلمات افراد را بدون تکیه بر میکروفون رمزگشایی کنند.
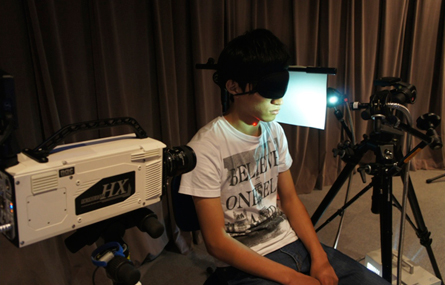
پژوهشگران با گرفتن هزاران عکس در هر ثانیه، هر حرکت ارتعاشی گوشت گردن را که با صداهایی از حنجرهی فرد همراه بوده است، ثبت کردند. سپس یک برنامهی رایانهای این ارتعاشات پوست را به صدا تبدیل کرده است. یاسوهیرو اوکیاوا (Yasuhiro Oikawa) از دانشگاه واسدا (Waseda University) در توکیو این کار را در سوم ژانویه در کنگرهی بینالمللی آکوستیک گزارش کرده است.
اوکیاوا میگوید که نرمافزارهای استاندارد لبخوانی حرکات ناگهانی لب، حرکات سریع زبان و تکانهای فک را هنگام صحبت کردن شخص دنبال میکنند. برخی از برنامهها بهاندازهی کافی توانمند هستند تا زبانهای مختلف را تشخیص دهند، اما کامپیوتر چیزی بیش از یک متن نمیتواند ارائه دهد.
اطلاعات متنی مهم هستند اما به همان اندازه تکیهی صدا، زیروبم و بلندی آن اهمیت دارد. او میگوید: «ما از طریق صدای گوینده به احساس او پی میبریم.»
میکروفون نیز مشکلاتی دارد: میکروفون اغلب نویز زمینه را نیز ثبت میکند مثل صدای زوزهی باد یا صدای بلند افتادن یک قطرهی باران که میتواند مانع شنیدن صدای فرد شود. بنابراین اوکیاوا و همکارانش در جستجوی روشی بودند تا بتوانند صدای انسان را ضبط کنند.
این پژوهشگران با استفاده از یک دوربین با سرعت بالا، گلوی دو داوطلب را بزرگنمایی کردند و سپس تصویر گلوی آنها را هنگام گفتن کلمهی ژاپنی tawara (俵) بهمعنی عدل کاه یا کیسه ثبت کردند. کار ثبت تصاویر با سرعت 10 هزار فریم بر ثانیه انجام شده است؛ سرعت معمول برای نمایش فیلم در سالن سینما 24 فریم بر ثانیه است.
در همان زمان گروه اوکیاوا کلمات داوطلبان را با یک میکروفون استاندارد و یک لرزشسنج ثبت کردند؛ دستگاهی که میزان لرزش پوست آنها را اندازه میگرفت.
اوکیاوا میگوید: «ارتعاشات گلو که بهوسیلهی دوربین ثبت شده است، مشابه ارتعاشات جمعآوری شده توسط میکروفون و لرزشسنج است.»
او میافزاید: «زمانی که این گروه این دادههای ارتعاشی را از طریق یک برنامهی رایانهای اجرا کرد، توانست صدای داوطلبان را به خوبی بازسازی کند، بهگونهای که کلمهی گفته شده قابل فهم بود.» او تصور میکند که قبل از پایان سال بتواند یک جمله را با استفاده از این روش ضبط و پخش کند.
کلاری پرادا (Claire Prada)، فیزیکدانی از مرکز ملی تحقیقات علمی در پاریس، معتقد است که این روش به دانشمندان این اجازه را میدهد که حتی در صورت وجود نویز زیاد زمینه قادر به شنیدن کلمات باشند. از نظر او این کار نویدبخش است اما هنوز تنها در حد اثبات یک اصل است.
اما سایر دانشمندان حاضر در محل انجام آزمایش مردد به نظر میرسیدند. وایکنگ جیانگ (Weikang Jiang)، مهندس مکانیکی از دانشگاه شانگهای جیائو تانگ چین (Shanghai Jiao Tong University) اشاره میکند که اوکیاوا صدای بازسازی شده را به نمایش نگذاشته، در عوض تصاویر امواج صوتی را نشان داده است. او تازگی کار را تحسین نمود اما گفت: «اوکیاوا نتایج را به ما نشان نداد.»
در گام بعدی او میخواهد دوربین را روی گونههای افراد متمرکز کند تا مکانهای بیشتری از پوست را که در هنگام صحبت به آهستگی تکان میخورند، جستجو کند. تجزیهوتحلیل ناحیههای مرتعشِ بیشتری میتواند به پژوهشگران اطلاعات اضافی در مورد صدای فرد دهد و این میتواند بازسازی صدا را بهبود بخشد.
منبع:
مرجع:
http://asadl.org/jasa/resource/1/jasman/v133/i5/p3297_s3?bypassSSO=1
نویسنده خبر: مونا عجمی
آمار بازدید: ۳۵۹
ارجاع دقیق و مناسب به خبرنامهی انجمن بلا مانع است.»


